摘要:本文介绍推荐系统中召回阶段的核心技术,包括双塔模型(DSSM)、正负样本构建策略、负采样技巧、线上召回架构、Deep Retrieval 等。
一、召回阶段的作用
推荐系统的召回阶段负责从百万级候选池中快速筛选出千级候选,送入后续的粗排和精排。
百万级物品 → 召回策略(多路) → 千级候选 → 粗排 → 精排
召回的核心要求是:高召回率 + 低延迟,宁可多放几个可疑的,也不能漏掉用户感兴趣的。
二、双塔模型(DSSM)
2.1 核心思想
双塔模型将用户和物品分别编码为向量,通过向量相似度(通常是余弦相似度)来衡量匹配程度:
用户特征 → [用户塔] → User Embedding (128维)
↓
cos(u, v)
↓
物品特征 → [物品塔] → Item Embedding (128维)
这样做的好处是:物品向量可以预先计算并存储,在线召回时只需计算用户向量,然后做最近邻搜索。
2.2 训练方式
Pointwise(点对点)
将每个用户-物品对视为一个独立的二分类样本:
- 正样本:
cos(u, v+) ≈ 1 - 负样本:
cos(u, v-) ≈ -1 - 正负样本比例通常设为 1:2 或 1:3
用户 u ──▶ 正样本物品 v+ → 标签 1
用户 u ──▶ 负样本物品 v- → 标签 0
Pairwise(成对比较)
每次取一个正样本和一个负样本,学习让正样本的相似度大于负样本:
-
Triplet Hinge Loss: \(L = \max(0, \cos(u, v^-) + m - \cos(u, v^+))\) 其中 $m$ 是 margin,通常取 0.1~0.3
-
Triplet Logistic Loss: \(L = \log(1 + \exp[\sigma(\cos(u, v^-) - \cos(u, v^+))])\)
Listwise(列表比较)
每次取一个正样本和多个负样本,学习正样本在列表中的排名:
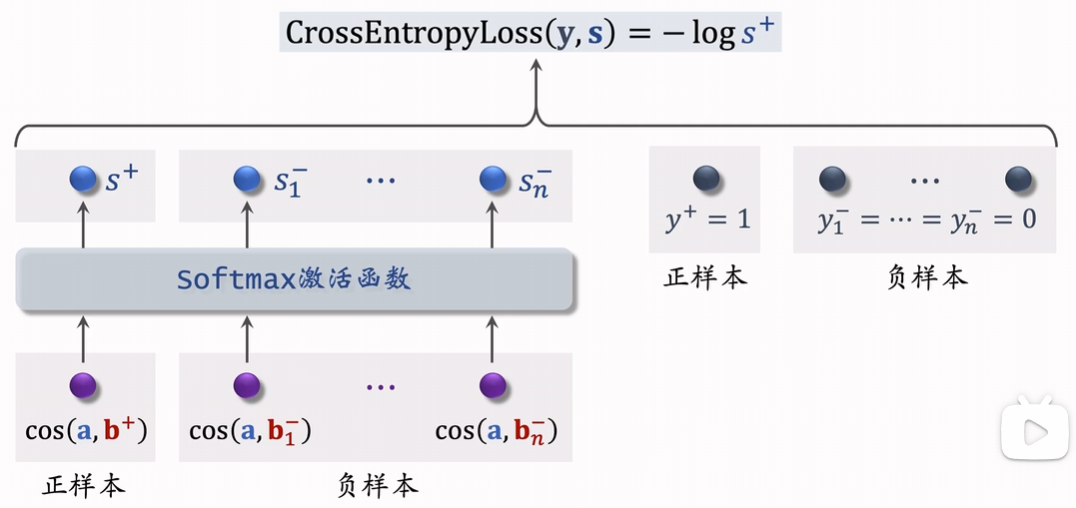
2.3 属性处理方法
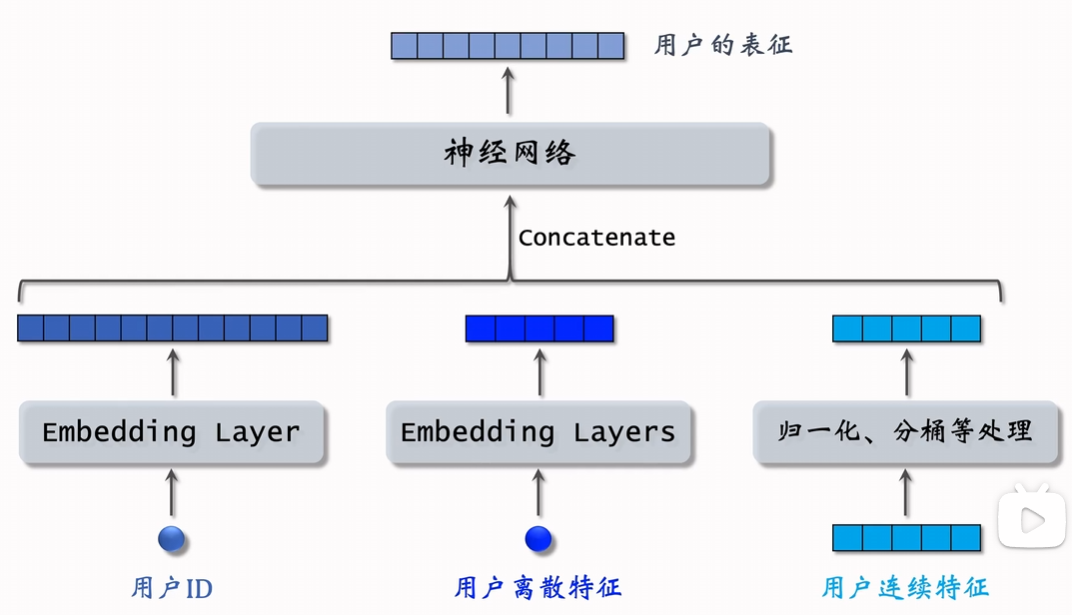
不同特征需要不同的处理方式:
- 连续特征:归一化或分桶
- 类别特征:Embedding 编码
- 序列特征:Attention 池化或 RNN 编码
三、正负样本构建
3.1 正样本
正样本定义为:曝光且有点击的用户-物品二元组。
注意事项:
- 需要对冷门物品过采样,否则热门物品会占据大多数正样本
- 或者对热门物品降采样,防止模型偏向热门物品
3.2 负样本
负样本分为三类,构建策略各有不同:
简单负样本(未被召回)
直接从全体物品中抽样:
- 均匀抽样:对冷门物品不公平,负样本大多是冷门物品
- 非均匀抽样:抽样概率与热门程度正相关,通常取点击次数的 0.75 次方(类似 Word2Vec 的负采样策略)
# 负采样概率
p(item_i) = count_i^0.75 / Σ count_j^0.75
困难负样本(召回但被淘汰)
这些物品被召回了,但在粗排或精排中被淘汰,没有被曝光。它们是最有价值的负样本,因为模型需要学习区分它们和正样本。
Batch 内负样本
将同一个 batch 中其他正样本的物品作为负样本:
- 问题:相当于对热门物品以点击次数抽样,没有加 0.75 次方
- 解决:训练时使用
cos(u, v_i) - log p_i校正,在线召回时不需要后一项
曝光未点击
被曝光但用户没有点击的物品。这类负样本不适用于召回模型训练,因为召回阶段还没决定曝光,它们更适合用于精排模型的训练。
四、线上召回架构
用户请求 → [用户塔] → 实时计算 User Embedding
↓
┌─────────────────────┐
│ 向量检索引擎 │
│ (Milvus / Faiss) │
│ 存储预计算的 │
│ Item Embedding │
└─────────────────────┘
↓
Top-K 召回结果
关键设计
- 用户塔在线计算:用户兴趣是动态变化的,不能预计算
- 物品塔预计算:物品特征相对稳定,可以每天/每小时批量更新
- 向量检索引擎:使用 Faiss、Milvus 或 HnswLib 做最近邻搜索
五、模型更新
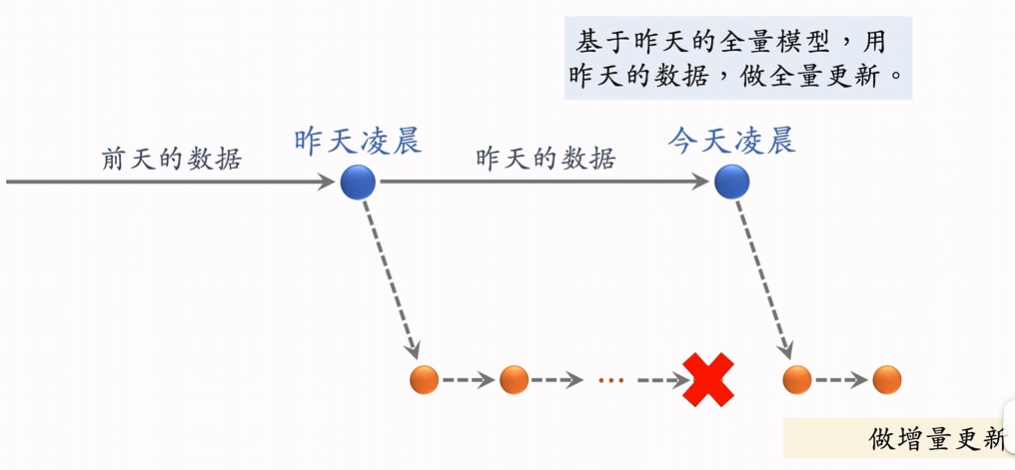
5.1 全量更新
- 每天凌晨用昨天全天数据训练模型
- 初始参数是昨天的旧模型参数
- 数据随机打乱后训练 1 个 epoch
- 优点:对数据流和系统的要求较低,训练稳定
5.2 增量更新(Online Learning)
- 实时收集线上数据,做流式处理
- 生成 TFRecord 文件,增量训练模型
- 只更新用户 embedding 参数,增量更新参数不用于全量更新
- 缺点:只使用短时间数据,存在较大偏差
- 优点:能快速响应用户兴趣变化
5.3 两者的权衡
| 维度 | 全量更新 | 增量更新 |
|---|---|---|
| 数据量 | 全天数据 | 短时间数据 |
| 训练稳定性 | 高 | 低 |
| 实时性 | 低(T+1) | 高(分钟级) |
| 适用场景 | 通用召回 | 兴趣变化快的场景 |
通常两者结合使用:每天全量更新作为基准,增量更新补充实时兴趣。
六、自监督学习训练物品塔
在缺乏标注数据时,可以用自监督学习预训练物品塔:
| 方法 | 描述 |
|---|---|
| Random Mask | 随机 mask 部分特征,让模型重建 |
| Dropout | 随机 dropout 部分特征,增强鲁棒性 |
| 互补特征 | 使用同一物品的不同特征视图做对比学习 |
| Mask 关联特征 | 将一组关联特征同时 mask,学习跨特征的关联 |
七、其他召回策略
7.1 Deep Retrieval 召回
将召回过程建模为树搜索问题,使用 Beam Search(贪心算法)在物品树中寻找最优路径。优势是可以处理大规模候选池,但构建物品树需要精心设计。
7.2 地理位置召回
- GeoHash 召回:将经纬度编码为 GeoHash,召回同 GeoHash 的物品
- 同城召回:直接召回用户所在城市或附近的物品
7.3 作者召回
召回用户关注/喜欢的作者发布的新内容。适用于社交属性强的产品。
7.4 曝光过滤
使用 Bloom Filter 记录用户已经看过的物品,召回阶段直接过滤掉,避免重复曝光。
八、总结
召回阶段的关键要点:
- 双塔模型:将用户和物品映射到同一向量空间,支持快速检索
- 负样本构建:简单负样本 + 困难负样本 + Batch 内负样本,多管齐下
- 线上架构:用户塔实时计算 + 物品塔预计算 + 向量检索引擎
- 模型更新:全量 + 增量双管齐下,兼顾稳定性和实时性
相关文章: